
728x90
반응형
오랜만에 쓰는 파이썬초보만 블로그
드디어 파이썬을 써보게 되었다.
최근 여건이 더 좋은 곳으로 이직을 하였는데, 개발 직군이 아니라 프리세일즈쪽으로 왔다.
제안서 작성부터 여러 가지 일을 하고 있지만 개발이 필요한 시점에서 Python을 다루는 기회가 닿은 것이다.
거두절미하고 열심히 해보자!
read_csv_rows
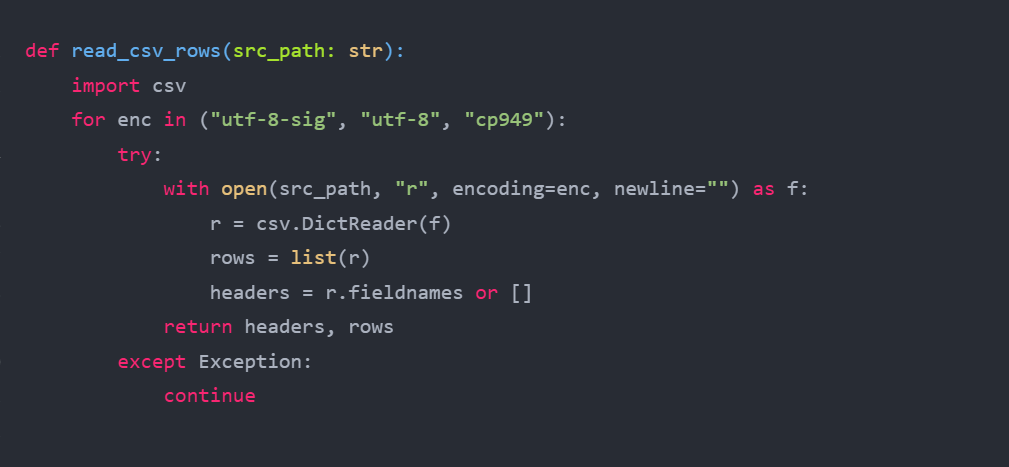
def read_csv_rows(src_path: str):
import csv
for enc in ("utf-8-sig", "utf-8", "cp949"):
try:
with open(src_path, "r", encoding=enc, newline="") as f:
r = csv.DictReader(f)
rows = list(r)
headers = r.fieldnames or []
return headers, rows
except Exception:
continue
f : 실제 파일을 여는 file handle로서 작동한다.
- enc : utf-8-sig > utf-8 > cp949 순서로 인코딩을 재시도
- newline="" : 파이썬 CSV 모듈 권장값, 줄바꿈 처리 꼬임 방지
- csv.DictReader(f) : f를 넘겨받아 줄 단위로 읽음
r : CSV 첫 줄을 header로 삼아 각 행을 dict로 내놓는 Iterator 역할을 한다.
- rows = list(r) : r을 한 번에 리스트로 소비 > r 소진
- headers = r.fieldnames or [] : DictReader가 잡아둔 header 배열을 꺼내 header가 없으면 빈 리스트로 인식
from openpyxl import load_workbook
wb = load_workbook(filename=src_path, read_only=True, data_only=True)
try:
ws = wb.active
rows_iter = ws.iter_rows(values_only=True)
try:
headers = [str(h).strip() if h is not None else "" for h in next(rows_iter)]
except StopIteration:
return [], []
rows = []
for row in rows_iter:
d = {}
for i, h in enumerate(headers):
d[h] = "" if i >= len(row) or row[i] is None else str(row[i])
rows.append(d)
return headers, rows
finally:
wb.close()
wb : workbook 객체로서 엑셀 파일 전체를 의미한다.
- read_only=True : 메모리 사용을 줄이고 속도 향상
- data_only=True : 수식이 아닌 계산값을 읽음
ws : worksheet 객체로서 wb.active는 첫 sheet를 의미한다.
rows_iter : sheet의 row Iterator 역할을 한다.
- value_only=True : 각 행이 셀 값 튜플로 나옴
headers : 첫 행을 꺼내 header 리스트로 변환한다.
- None이면 ""로, 값이 있다면 str(h).strip()으로 문자열화
- StopIteration : 시트가 비면 [], [] 로 반환
wb.close() : file handle을 확실히 닫아 윈도우에서 잠금 누수를 방지한다.
add_desc
def add_desc(headers, rows):
def pick(row, *keys):
for k in keys:
if k in row and row[k] is not None:
v = str(row[k]).strip()
if v:
return v
return ""
if "desc" not in (headers or []):
headers = list(headers or []) + ["desc"]
for row in rows:
v_id = pick(row, "id", "ID")
v_nm = pick(row, "이름", "name", "Name")
v_sex = pick(row, "성별", "gender", "Gender")
v_age = pick(row, "나이", "age", "Age")
row["desc"] = f"{v_id} {v_nm} {v_sex} {v_age}".strip()
return headers, rows
pick(row, *keys) : 주어진 row에서 keys후보들을 왼쪽부터 차례로 검사해 처음으로 실질적으로 값이 있는 필드를 선택한다.
- if k in row and row[k] is not None : 키가 존재하고 값이 None이 아니면 후보로 인정
- v = str(row[k]).strip() : 숫자, 날짜, Boolean 등 타입들을 문자열로 통일하고 양끝 공백 제거
if "desc" not in (headers or []) : 기존 headers 리스트에 desc 칼럼이 없으면 뒤에 추가한다.
'프로그래밍 언어 > Python' 카테고리의 다른 글
| [ Docker ] Docker Desktop 설치 및 Open WebUI 연결 (0) | 2025.09.04 |
|---|---|
| [ Python ] Open WebUI 커스터마이징 - file upload(2) (0) | 2025.09.03 |
| [ Python ] Open WebUI 커스터마이징 - csv 파일(3) (0) | 2025.09.03 |
| [ Python ] Open WebUI 커스터마이징 - csv 파일(2) (0) | 2025.09.03 |




